[논문 정리] Translation in Multi-modal Learning 논문 정리
여러 종류의 data 가 많다는 가정 하에, 우리는 많은 가정들을 세울 수 있다. "사람의 음성과 문장, 그리고 행동은 그 사람의 감정을 잘 맞출 것이다." 라는 것과 같이 말이다.
최근, Multi-modal learning 분야를 보면서, 이런게 진짜 end-to-end 구나 라는 생각이 들었다. 가지고 있는 데이터를 전부 각기 다른 vector space 로 보내서, 합쳐버리는데, 이 때 어떻게 합칠 것인지도 학습하는 이런 학습 방법은, 다양한 아이디어를 모델까지 부드럽고 효율적으로 이어주는데 중요한 역할을 할 것으로 느껴진다.
Multi-modal 분야의 survey 논문을 보니, 해당 영역은 크게 아래와 같이 4가지로 나뉘어진다.
- Representation : multiple modalities 를 어떻게 잘 결합할 것이냐에 대한 부분이다. Joint 와 Combined 방법이 있다고 한다. neural network의 경우에는 어떻게 잘 vector representation 을 할 것이냐에 대한 것이다.
- Translation : 하나의 modality 가 다른 modality 로 옮겨져 갈 때, 이 관계를 학습하는 것이다. uni-modality 를 예로 들면, 한국-영어 번역 모델이 있고, multi-modality 의 경우, 문장을 쓰면, 그 문장이 이미지화 되는 것이 있다.
- Alignment : multi modality 간의 직접적인 관계를 학습하는 것으로, 내가 이해한 바에 따르면 multi-modal pair (x,y,z) 짝지어서(align) 이들의 조합 자체를 학습하는 것이다.
- Fusion : multi-modality에서 나온 각각의 정보를 잘 조합해서 최종 예측에 사용하는 것이다.
위의 분류가 다른 곳을 봐도 많이 쓰이는 것을 보아, 어느 정도 확립된 분류같은데, 뭔가 분명하지 않은 구분인 것 같아 조금 혼란스러웠다. 그 중, 나름 고유한 분야로 보이면서 회사에서 쓸 수 있을 것 같은 상상력이 솟아나는 분야인 Translation 관련 논문을 몇 개 가볍게 읽었고 이에 대한 정리를 해보려 한다.
본격적인 논문 정리에 앞서, 내가 읽은 적은 양의 논문 샘플에 따르면, 많은 모델들이 sequence to sequence 의 양상을 띄고 있다. (transformer architecture 적합) 이에 따라, seq2seq 아키텍처를 알고 있다면 많은 논문들은 편하게 읽을 수 있지 않을까 싶다.
Language2Pose: Natural Language Grounded Pose Forecasting [링크]
제목부터 translation 을 암시하고 있는 논문이다. 문장을 치면, 그에 맞는 pos 의 sequence (video) 를 학습하는 것이다.

위에서 언급한 바와 같이, encoder-decoder 의 형태를 띄고 있다. 위의 이미지를, encoding input 으로 language(text)만 넣는 것이 아니고, output 인 pos 도 같이 본다. 하지

하지만, 두 개의 encoder는 독립적으로 학습되는 모델로 위의 식과 같이 파라미터를 서로 공유하지 않는다.
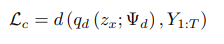

하지만, decoder를 하나로 같이 쓰게 되는데, 이 decoder 를 통해 두 개의 loss 가 산출된다. 하나는 output 인 pos sequence 의 manifold 를 얼마나 잘 학습했는 지에 대한 reconstruction loss 이고, 다른 하나는, encoded text embedding 이 얼마나 잘 pos 를 generate 하는 지에 대한 cross modal loss 이다.
두 개의 loss 는 보완적인 성격을 띄고 있으며, (좋은 pos manifold 는 효율적인 cross modal이 가능) 두 loss 를 더함으로써, jointly 학습시키게 된다.
Reconstructing faces from voices [링크]

해당 논문은, 목소리를 듣고 발화자의 얼굴을 생성하는 테스크로 매우 흥미로운 테스크이다. (이게 진짜로 된다고?! 이랬다..) GAN 은 auto-encoder 와 같이, 자기 자신을 넣고 진짜 데이터인지 생성된 데이터인지를 맞추는 방식으로 학습된다. 해당 논문에서는, 이런 학습 메카니즘의 인풋 부분만 multi-modal로 바꿔서 학습을 진행한다. True 의 경우, 실제 발화자의 이미지 벡터이고, False의 경우, 모델이 생성한 이미지이다.
안 그래도, GAN 의 학습이 까다로운데 multi-modality domain 에서는 아마 더 어려울 것으로 보인다. 실제 논문에서도 생성된 이미지의 품질보다는 결과의 합리성에 초점을 맞추고 있다.

Found in Translation: Learning Robust Joint Representations by Cyclic Translations Between Modalities [링크]

개인적 느낌으로는 multi-modality learning 의 분야에서 fusion에 가깝지 않나 라는 생각이 들지만, fusion task 를 위해 translation 분야를 도입한 것으로 해석하여 정리를 하려 한다. 해당 논문은 문장(text)과 발화 모습(video)에 따른 발화자의 감성을 "예측" 하는 테스크이다.
위의 이미지에서 왼쪽의 네모 박스는 위에서 언급한 encoder-decoder 를 따르고 있다. 다만 여기서 이전과 다른 점은, 1번부터 4번으로 나아감에 따라, Input-Output pair 를 바꿔서 진행한다는 것이다. 즉, Source-Target 이 교환되면서 같은 encoder-decoder parameter 가 학습된다. 이에 따라, cyclic 이라는 말이 붙는다. (물레 방아 같다)
이러한 학습과정을 통해 나온 encoder 의 output (decoder 의 input)은 이상적으로, modality간, relational-infomration 이 잘 임베딩되어 있을 것이다. 이 임베딩을 classifier 의 인풋으로 삼아, sentiment 분류 문제를 학습한다.

여기서, loss function은 classification loss 한 개만 사용된다. cyclic 하게 할 수 있는 것은, translation 의 형태를 띄지만, 결국 다수의 modality 들이 모두 input 으로 사용되는 형태인 fusion 을 따르고 있기 때문이다.

위는 긍정적 비디오와 부정적 비디오의 임베딩을 (여기서 임베딩은 classifier 의 input 을 의미한다) 차원 축소해서 본 것이다. (a) 보다 cyclic translation을 한 (b), (c) 가 상대적으로 잘 라벨을 분류하고 있는 것으로 보인다.
Conclusion
글쓰기가 다 끝나갈 무렵 드는 생각은, 사실 multi-modal 의 분류는 결국 neural network last layer보다 밑 단에서 어떻게 multi-modality 를 학습해나갈 것이냐의 문제이지 않을까 라는 생각이 들었다. (그렇다면 모두 fusion 인 것인가...)
아무쪼록,
multi-modality learning 에서 translation 분야는, 다수의 vector space 를 단순히 합치는 게 아닌, space 를 어떻게 건너 다녀야 할지를 학습하는 방법이라고 생각한다. 하나의 modality 에서 이야기하는 어떤 이벤트가 다른 modality 에서는 어떻게 표현될 수 있는지를 학습하는 방법이다.
어떻게 쓰일 지 상상력을 잘 주무르면 재밌는 것이 나올 수 있는 분야라고 보인다.