[개발 정리]/[data engineering]
[MlOps] Data Engineering in Uber (1)
hskimim
2021. 9. 11. 18:10
MlOps 에 관심을 가지게 된지 얼마 안된터라, 이분야가 대체 어떤 것이고 뭐부터 공부해야 할지 막막했던 차에, 구세주를 찾았으니 바로 Uber Engineering Blog 이다.
서비스를 제공하면서 그 과정에서 가졌던 이슈들과 프레임워크들을 공유해주는데, 실무에서 사용되는 다양한 기술들과 주요 이슈들을 체크하기에 너무 좋은 자료들이라 정리하려 한다. 정리는 한 source posting 당 또는 source posting의 주제를 나름대로 묶어서, 하나의 포스트로 짧게 정리해 가볍게 진행한다.
Meet Michelangelo: Uber’s Machine Learning Platform [원글]
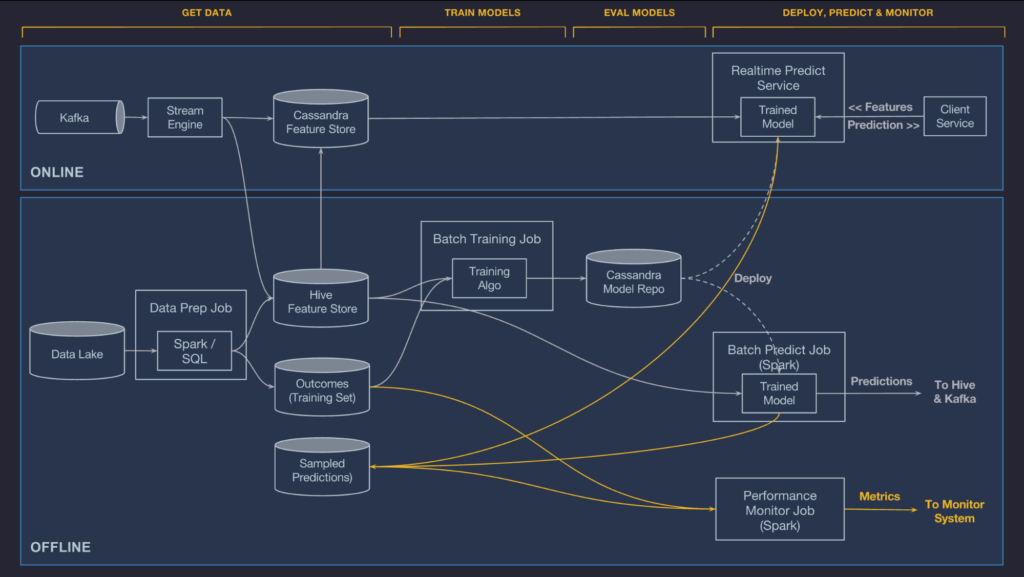
- 데이터 관리
- 파이프라인 요구 사항:
- 확장 가능
- 성능 우수
- 데이터 플로우와 품질 모니터링 지원
- 온라인, 오프라인 학습 및 예측을 지원
- 오프라인 :
- 온라인 :
- 오프라인과 같이 HDFS 에서 읽어오는 것이 불가능
- 필요한 feature들을 Cassandra 에 올려서 낮은 latency로 읽어오게 한다.
- feature store :
- Centralized : 모델을 만들 때, 하나의 feature store가 관리하는 (ex.versioning) 저장소에 접근해야 함
- daily-updated (time-series) : 매일매일 정해진 feature 가 업데이트된다.
- 파이프라인 요구 사항:
- 모델 학습
- 오프라인 분산 교육 시스템 지원
- YARN, MESOS : 분산 시스템을 관리해주는 툴
- 모델 아키텍처 + 파라미터 + 하이퍼파라미터 + 성능 지표가 모델 저장소로 옮겨져 관리된다.
- Mlflow 의 Model registry 와 같은 지원
- 오프라인 분산 교육 시스템 지원
- 모델 평가
- feature contribution
- metric visualization
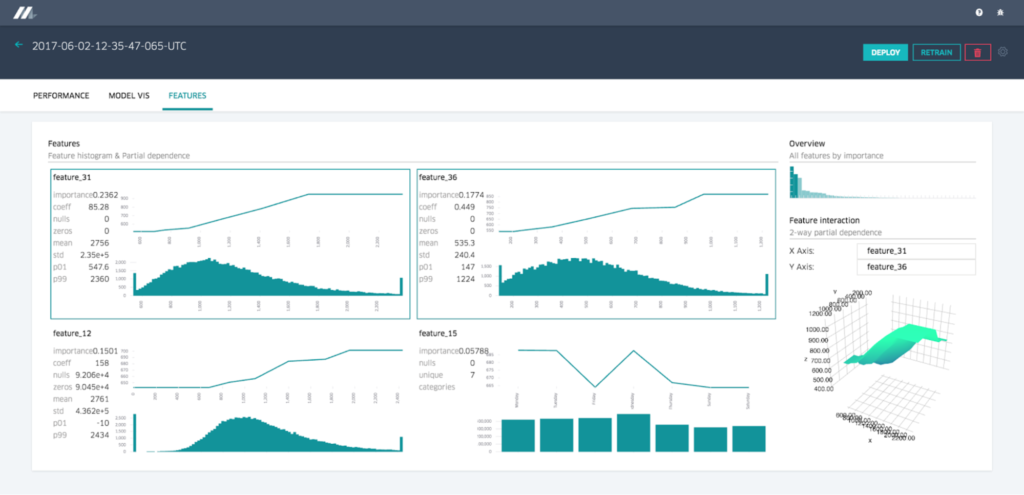
example of feature visualization
- 모델 배포
- 오프라인 : 컨테이너에 배포하고, Spark 에서 실행하여, 배치단위로 예측해 Hive나 Cassandra에 저장
- 온라인 : 예측 서비스 클러스터에 배포하여 분산 처리로 실시간 예측 지원
Conclusion
Uber 사내의 machine learning platform의 전반적인 플로우와 사용하는 프레임워크들을 살펴봤는데, 블로그 초반에서 사용하는 오픈 소스로, HDFS , Spark , Samza , Cassandra , MLLib , XGBoost, TensorFlow 를 언급하였는데, 많은 부분들이 Apache 재단에서 나온 프레임워크들인 걸 알 수 있었다.
사용할 라이브러리를 선택할 때마다, 엔지니어들이 많은 고민을 했을텐데, 이 글을 읽는 것만으로는 그런 것을 느끼기에는 (당연하지만,) 한계가 있는 것 같다... 언급된 라이브러리들을 써보면서 미켈란젤로 플랫폼의 플로우를 모방하여 만들어보면, 각 라이브러리에 대한 특징을 파악할 수 있는, 좋은 연습이 될 것 같다.