[간단 정리] model calibration 에 대해 알아보자 (1)
model distilation 논문을 보면, teacher model이 주어진 input 에 대한 예측값, 더 정확히는 특정 class labels 에 할당된 predicted probability 을 사용해 student model 을 학습시킨다. 이는, 모델이 주는 probability 는 모델의 knowledge 라고 할 수 있음을 시사한다.
calibration 이란 예측된 probability 가 옳음의 우도 (likelihood of correctness) 를 나타내게 하는 task 를 의미한다. 한 논문의 예시를 가지고 와보면, 100개의 예측값이 있다고 하고 모델이 특정 class label 에 대한 예측 probability/confidence (probability 는 불확실성을 내포하기 때문에, probability 값의 정도는 예측값에 대한 confidence 라고 할 수 있다..) 으로 0.8을 반환했을 때, 80개 정도가 잘 분류되면 perfect calibration 이며, calibration task 는 이를 목표로 한다.
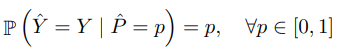
시각화를 통해 calibration 에 한발짝 더 다가가보자.
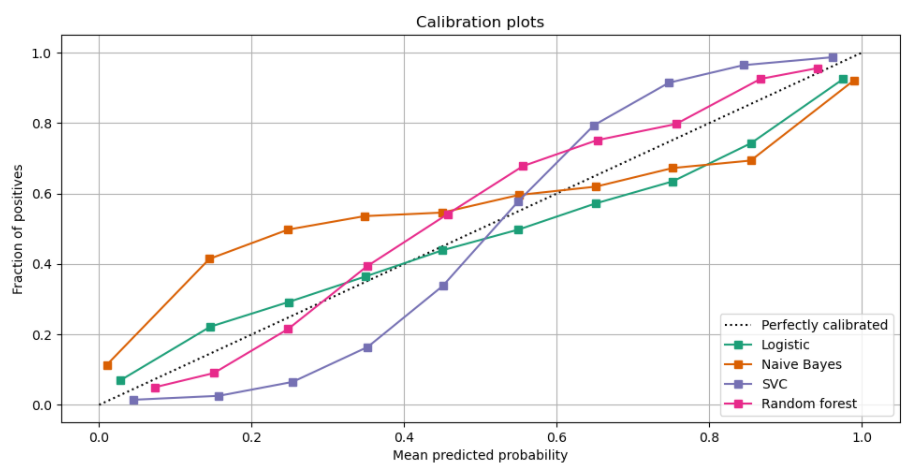
아래는 sklearn User Guide에서 가져온 이미지로 "calibration curve" 라고 불리는 plot 이다. 해당 plot 은 binary label 에 한정하여, calibration 의 경향을 보여주는 지표이며. multi-class 에 대해서는 one-to-rest 의 방법으로 만들어서 전자의 class 에 대한 calibration 에 집중하는 형태가 있고, sklearn.calibration.calibration_curve 함수는 이를 모두 지원한다.
calibration curve plot 의 x-axis 는 모델이 특정 입력값에 대해 positive(1)로 반환한 predicted probability를 기준으로 나열한 것이다. 실제로는 binning을 사용하며 [0,1] 사이의 값을 균등하게 또는 weighted 의 형식으로 categorize 를 한다.
y-axis 는 x-axis 에 매칭되는 입력값들이 실제로 positive(1)인 통계량을 의미한다. 이에 따라, calibration curve 가 y=x 의 기울기가 1인 일직선을 따르면, perfect calibration 이 된다.
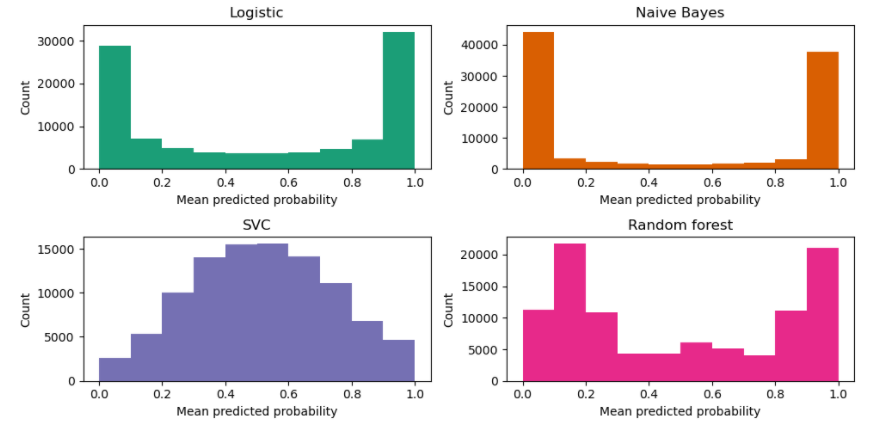
calibration 이라는 task 가 있다는 것은, machine learning 모델이 poorly-callibrated 의 경향이 존재한다는 것을 의미한다. 이는 모델의 특성에 따라 충분히 예상되는 결과이며, poorly-calibrated 되는 경향성 (probability distribution) 또한 다 다르다. 아래 이미지는 위와 같은 sklearn User Guide에서 가져온 이미지로 같은 데이터에 대해, 각기 다른 예측 확률 분포를 보여주고 있다.
model calibration은 다양한 형태로 이뤄지는데, 하나는 train dataset 에서 model 을 학습시켜서, 학습된 확률값 p_hat 를 가지고 validate dataset 에서 이를 post-processing 하여 p_hat_calibrated 을 취하는 방식이 있다. 또 다른 하나는 모델을 train dataset 학습하는 과정에서 calibration 을 돕는 테크닉을 사용하는 방식으로 해당 테크닉들이 가지는 파라미터들을 fine-tuning 하기 위해 validate dataset 이 사용된다.
calibration 테크닉에 대해서 다루기 전, calibration 에 대한 성능 지표들이 무엇이 있는지 최소한으로 한 번 알아보려 한다. 지금까지 읽어오는 데에 큰 어려움이 없었다면, 성능 지표에 대한 부분도 큰 문제 없이 이해할 수 있을 것이다.
수식에 대한 이미지의 캡쳐는 논문을 참고하였다. (1), (2)
Expected Calibration Error (ECE)
논문을 읽다보면, 제일 많이 나오는 성능 지표이다. 말 그대로 평균값을 사용하는데 수식은 아래와 같다.
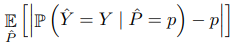
predicted probability 와 이에 응하는 real probability 의 차이의 절댓값을 평균낸 것이다. 위의 calibration curve 로 설명해보자면, scatterplot 에 y = x 선을 그리고 각 data point가 선에서 떨어진 만큼의 거리를 평균낸 것이라고 할 수 있다.
위의 식의 문제점에 문제점이 있는데, 바로 probability distribution 을 나누는 것에서 발생한다. 예로 들어 설명해보자면, 위의 그림에서 Naive Bayes 모델과 같이 predicted probability distribution 이 양 끝의 tail 에 치우쳐져 있는 경우를 생각해보자. 이런 경향성에도 불구하고 [0,1] 의 구간을 균등하게 0.1로 10개 나눠서 10개의 data point 를 가지고 평균을 낸다면, 전체를 대표할 만한 평균값을 얻기 어려울 것이다. 이에 따라, 아래의 weighted ECE 는 각 binning 에 속한 모델의 예측값을 가충평균을 사용하여 성능 지표를 계산한다.

Maximum Calibration Error (MCE)
모델의 calibration 이 중요한 분야는 모델의 예측에 대한 risk 가 높은 분야가 많다. 이에 따라, poorly-calibrated 경우에 민감하게 반응하는 것이 중요하기 때문에, miss-calibrated 된 경우들 즉, 거리들의 최댓값을 성능 지표로 사용하는 경우이다.
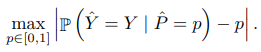
위의 방법들이 실질적으로 널리 사용되지만, 모델의 predicted probability 의 분포를 히스토그램으로 binning 한다는 것이 어찌보면 approximation 의 형태를 띄기 때문에, 더 좋은 근사에 대한 제시들이 많이 이뤄지고 있다. 기존의 방법론이 가지는 한계점과 이를 보안하여 제시된 방법론에 대해 하나 알아보고 성능 지표 설명을 마쳐보겠다.
Adaptivity :
bin 의 크기를 작게 만들게 되면, 추정하는 데이터 셋에서는 정확한 성능 지표를 계산할 수 있겠지만, 데이터가 존재하지 않는 bin이 많아지는 sparse 한 추정량이 만들어지면서, less-general 해진다. 이에 따라 위의 weighted 방법과 유사한 adaptive binning 을 제시하는 성능 지표가 존재한다.
Class Conditionality :
모델이 특정 class label 에 대해 가장 높은 확신으로 이야기하는 특정 label 에만 집중하며 성능 지표를 보는 것은, 2 번째 혹은 3 번째 class label 에 대한 calibration 성능을 보장할 수 없기 때문에, K개의 class 에 대한 성능을 독립적으로 보는 것에 대해 이야기한다.
Norm :
각 데이터 포인트와 y = x 선 간의 거리에 대한 측정을 어떤 것을 사용할 지에 대해서이다. 논문에 따르면 L1 보다 L2 가 calibration 최적화에 더 효과적이었다고 한다. 근데 모든 데이터, 모든 모델에 대해 그런 것은 아니었기 때문에, 분명한 경향성은 크게 보이지 않았다.
Adaptive Calibration Error (ACE)

절대값 안에 있는 식은 위의 ECE 와 동일하다고 보면 된다. K 는 클래스의 갯수이며 클래스 별로 ECE 를 측정하여 이를 평균낸다. R 은 데이터가 총 N 개일 때 이를 N/R 로 나누게 되는데, 즉 하나의 bin 에 들어있는 데이터 수를 의미한다. 쉽게 말하면 weighted ECE 는 균등 bin 을 쓰고 가중 평균을 사용했지만, adaptive ECE 의 경우 각 bin 에 같은 수의 데이터가 있게끔 하는 것이다.
느꼈겠지만, calibration 에 대한 metric 을 계산할 때, 개선의 여지가 많은 부분은 predicted probability 와 이에 대응하는 true y 에 대한 binning 에 대한 것이다. sklearn 에서 지원하는 calibration_curve 는 이러한 니즈에 맞춰 probability distribution 을 고려하는 옵션인 strategy argument 를 지원하며, 디폴트는 'uniform' 이니, 'quantile' 로 조정해서 사용하면 된다. 아래는 해당 부분에 속하는 실제 sklearn 소스 코드이다.
if strategy == "quantile": # Determine bin edges by distribution of data
quantiles = np.linspace(0, 1, n_bins + 1)
bins = np.percentile(y_prob, quantiles * 100)
bins[-1] = bins[-1] + 1e-8
elif strategy == "uniform":
bins = np.linspace(0.0, 1.0 + 1e-8, n_bins + 1)
else:
raise ValueError(
"Invalid entry to 'strategy' input. Strategy "
"must be either 'quantile' or 'uniform'."
)다음으로는 머신 러닝에서 사용되는 calibration method 에 대해 하나씩 알아보려고 한다. 우선 sklearn.calibration.CalibratedClassifierCV 모듈에 대해 알아본다. 글이 많이 길어진 관계로 2편에서 하도록 하겠다.