[논문 정리] A simple method for domain adaptation of sentence embeddings
NLP Task 를 해결하기 위해서는 자연어를 벡터로 어떻게 표현하는 것이 굉장히 중요하고, 이에 따라 임베딩 기술이 빠르게 발전해왔다. Word2Vec과 같이 단어에 벡터를 매핑시켜주는 것부터 시작해서 현재는 contextualized embedding와 같이 문맥을 알고 있는 문장 레벨의 임베딩 방법론들이 많이 나왔다. 최근의 임베딩 기법들은 일반화된 성능과 common sense 를 갖추기 위해 common corpus 에 학습을 하곤 하는데, 의학 분야와 같이 domain-specific corpus의 성격이 짙은 분야에서는 임베딩을 도메인에 적합하게 fine-tuning 해주는 과정이 필요하다. 이를 domain-adaptation이라고 하는데, 해당 방법에 대해 이미 많이 알려진 아키텍쳐로 간단하게 학습을 시킬 수 있는 방법을 제시한 논문을 소개한다.
아래의 모델 아키텍쳐는 우리가 흔히 알고 있는, classification model의 형태이다. sentence embedding 모델 위해 full-connected layer를 얹어 output dimension을 우리가 타겟팅하는 라벨의 갯수 차원으로 맞춰주고, softmax regression하면서, pre-trained 된 sentence embedding까지 학습을 시키게 되면, 라벨 정보를 담고 있는 문장 임베딩을 가지게 된다.
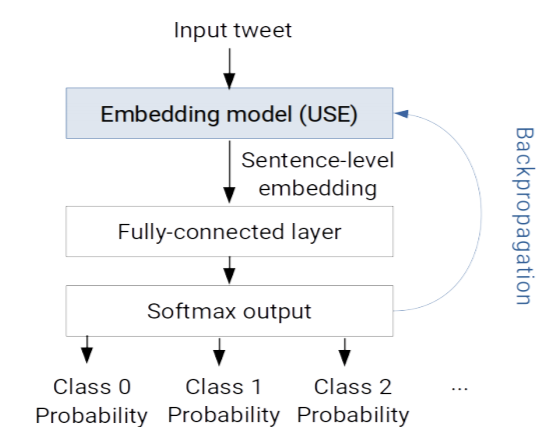
간단한 만큼 문제도 존재하는데, 첫 번째는 cacatastrophic forgetting 이라고 불리는 문제이다. 즉, 기존의 pre-trained sentence embedding이 가지고 있던 semantic information이 classification 과정 이후 사라지게 되는 것이다. 이러한 문제를 해결하기 위해서, 실제로 learning rate을 조절한다던지, layer를 한 층씩 activate 한다던지 다양한 방법들이 제시되었지만, 여전히 tricky 한 문제이다. 두 번째는, domain adaptatation을 하기 위한, classification 문제를 진행할 때, 여러 개의 데이터 소스가 학습 과정에서 합쳐지는 문제이다. 레이블의 형식이 다르거나, 스케일(class imbalance) 이 다른 경우, classification 학습 자체에 악영향을 끼치게 된다.
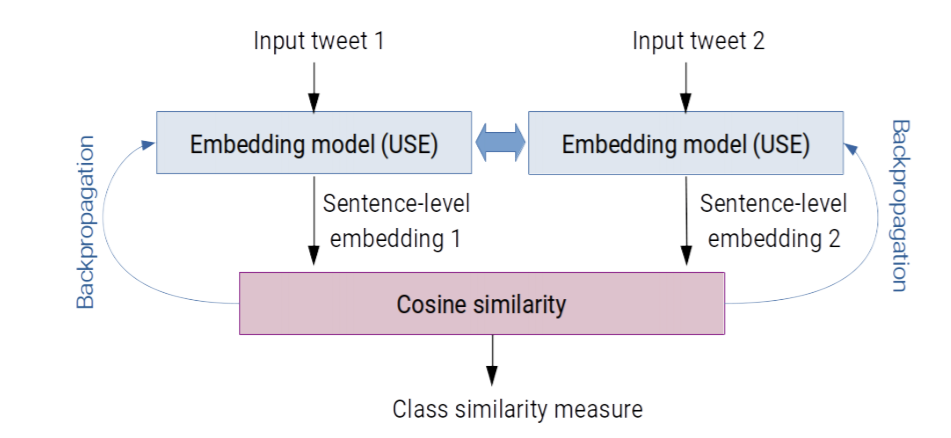
이에 따라, 저자가 제시하는 문제는 "해당 문장이 어떤 라벨에 속하는 지가 아닌, 두 문장이 같은 라벨에 속하는 문장인지를 구별하게 만들자" 이다. 우선 모델은 siamese network 로 model parameter를 sharing 하는 쌍둥이 embedding을 가지고 있는 모델이다. 방법은 매우 간단한데, 모델에 넣기 전, 데이터 셋을 pair 로 준비한다. 이때 pair 가 같은 클래스를 가지는 데이터 pair 과 다른 클래스를 가지는 pair가 되어야 하는데, 랜덤으로 세팅하면 되기 때문에, combination을 사용하거나, 랜덤 함수를 사용해 무작위 세팅을 하면 된다. batch-size가 N일 때, N은 같은 라벨 pair S와 다른 라벨 pair D의 합이 될 것이고, 같은 라벨 pair 문장 벡터 간 cosine-difference 에 다른 문장 벡터 간 cosine-difference를 빼주면 해당 모델의 loss 가 나온다. 모델이 잘 학습될 수록 아래 식 우변의 앞의 term이 작아지고, 뒤의 term 이 작아지기 때문에, loss 가 줄어들게 된다.

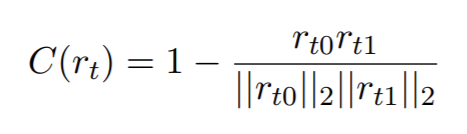
siamese network 을 학습시킬 때, negative sample 을 loss function에 같이 넣어주는 것이, (triplet loss) 모델 학습을 좀 더 어렵게 만들어준다는 것을 생각했을 때, 위의 loss function은 같은 맥락으로 해석될 수 있을 것 같다. 다만, 해당 모델은 주어진 label들이 independent 하다는 가정내에서 성립하기 때문에, 클래스를 세팅할 때 그런 부분을 실험자가 휴리스틱하라도 설정하고 학습을 시켜야 할 것 같다.
볼 수 있다시피, 모델의 로직이 굉장히 간단해서, 제공되는 pre-trained model을 가지고 현업에서 빠르게 활용하기 좋아보인다.