
TechY
[MlOps] Data Engineering in Uber (2) 본문
참고 자료 :
- https://forecasters.org/wp-content/uploads/gravity_forms/7-c6dd08fee7f0065037affb5b74fec20a/2017/07/Laptev_Nikolay_ISF2017.pdf
- https://eng.uber.com/monitoring-data-quality-at-scale/
- https://eng.uber.com/neural-networks/
- http://www.cs.columbia.edu/~lierranli/publications/TSW2017_paper.pdf
이번 포스팅에서는 파이프라인을 구축하기 위한 엔지니어링 요소보다는, 모델링에 대한 것을 다루려 한다. 두 가지 목적에 따른, 두 가지 모델에 대해서 이야기할 것이고 각각의 테스크는 아래와 같다.
- Extreme Event Forecast
- Data Quality Monitoring
두 가지 모두, 2017년도에 나온 포스팅이라 현재의 메커니즘과 많이 다르고, 트렌드성도 떨어지겠지만, 여전히 유용하게 쓰일 방법들이고, 아이디어가 좋아서, 정리하려 한다.
Time-series Extreme Event Forecasting with Neural Networks at Uber
Uber 의 business model 특성 상, 어느 시간대에 어느 곳에 서비스 수요자가 얼마나 있을 지를 예측하는 것은 매우 중요한 테스크이다. 이에 따라, 현재 상황을 feature 로 만들어서, 미래 시점의 수요자를 예측하는 forecast 문제를 푼다.
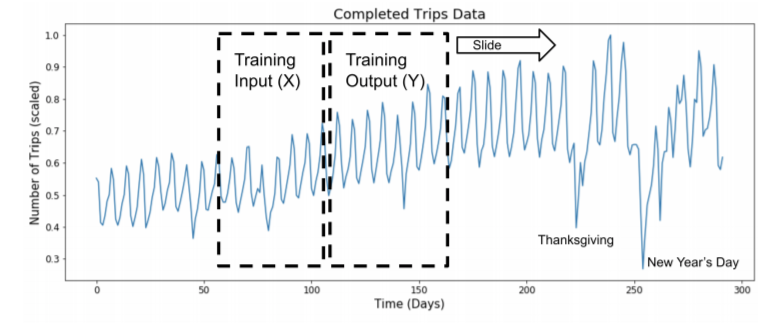
time series forecast 문제이기 때문에, 시간에 따라, 학습 데이터를 만들어주어야 하고, 방법은 아래와 같이 sliding window 를 주어 학습 데이터를 형성하였다. 다만 이 방법을 쓰면, 몇 가지 고려해야 할 점이 있는데, 첫 번째는, window 에 대한 도메인 지식이 필요할 것이다. 아래의 예시에는 50일이라고 했는데, 50일이여야 하는 이유를 EDA를 통해 정해야 한다. 두 번째는, window 길이를 중첩시키지 않고, 건너뛰면서 작업을 하면 window 크기 만큼, 데이터가 줄어들게 된다. 그렇다고, 계속 중첩을 시키면서 하게 되면, data instance 간 유사도가 너무 높아져서, input data X 의 i.i.d 조건이 깨지게 된다.
사실 데이터가 충분히 많다면, 걱정하지 않아도 될 문제지만, 그렇지 않다면 neural network 가 아닌 작은 통계적 시계열 모델을 사용하는 것이 보다 적합할 수 있다.
또한, Event detection task 를 푸는 이유로, uncertainty estimation 을 시도하였고, 방법은 dropout 을 통해, inference 값들의 uncertainty boundary 을 만들어주는 형태로 이뤄졌다. 후에, 이 값들은 평균과 같은 ensemble 기법으로 단일 값으로 합쳐지거나, 의사 결정의 tolerance 로 사용된다.
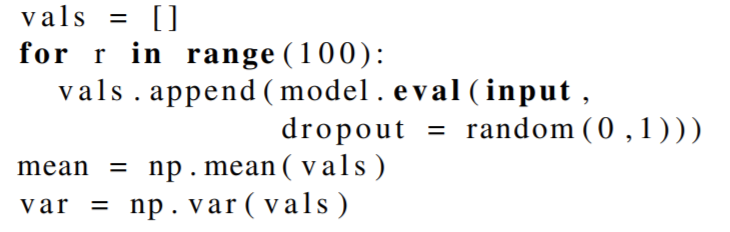
왼쪽 식은 모델의 예측값에는 두 가지 불확실성이 존재하는데, 모델에 주어진 "데이터", 그리고 모델에 주어진 "예측" 이렇게 존재한다. 이러한 불확실성을 각각 줄여주기 위해 모델을 LSTM autocoder 와 LSTM forecaster 라는 이름으로 두 개를 만들고 각각에 대한 uncertainty 를 측정하고 이를 줄여준다.
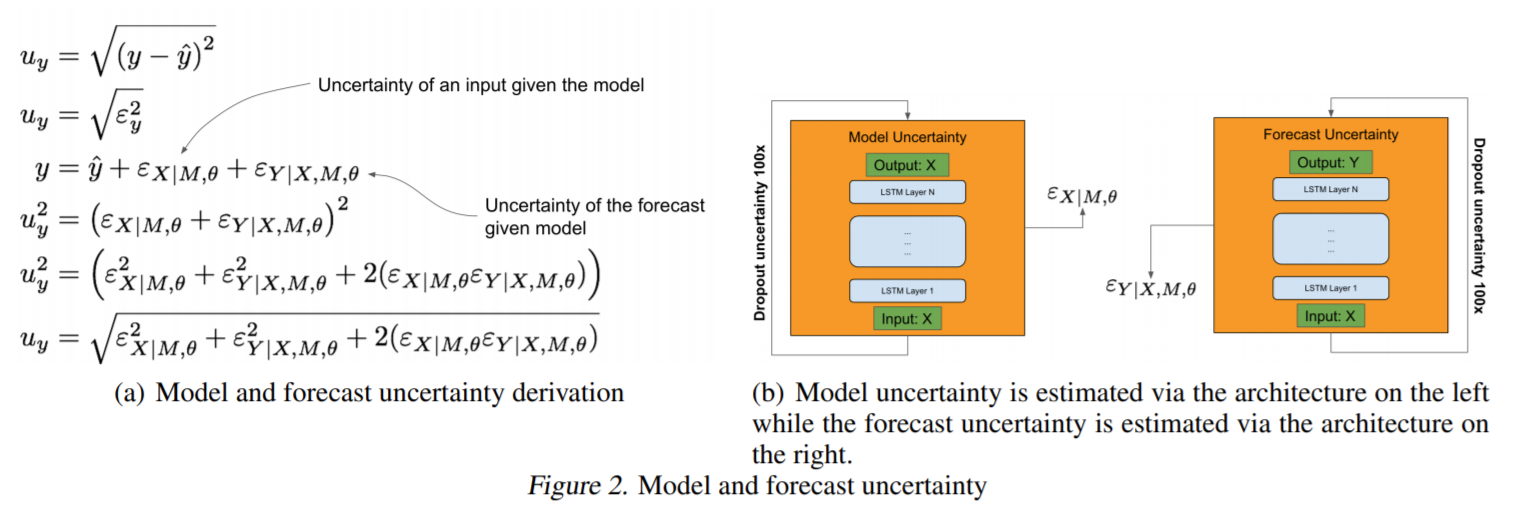
줄여주는 방법으로는, 처음에 LSTM auto-encoder 를 학습시킨 후, inference time 에 dropout 을 적용해 여러 개의 latent feature 를 만든 후, averaging 이나 concatenate를 사용해 합친다. 그리고 해당 값을 forecaster 의 입력으로 던져준다. 이로써, 입력값에 대한 불확실성을 줄여준다. 두 번째로 forecaster 에도 똑같이 dropout 을 적용해 여러 값의 최종 예측값을 만든 후, uncertainty boundary를 만들어주고, 이들의 평균을 사용한다. 이는 아래 그림과 같다.
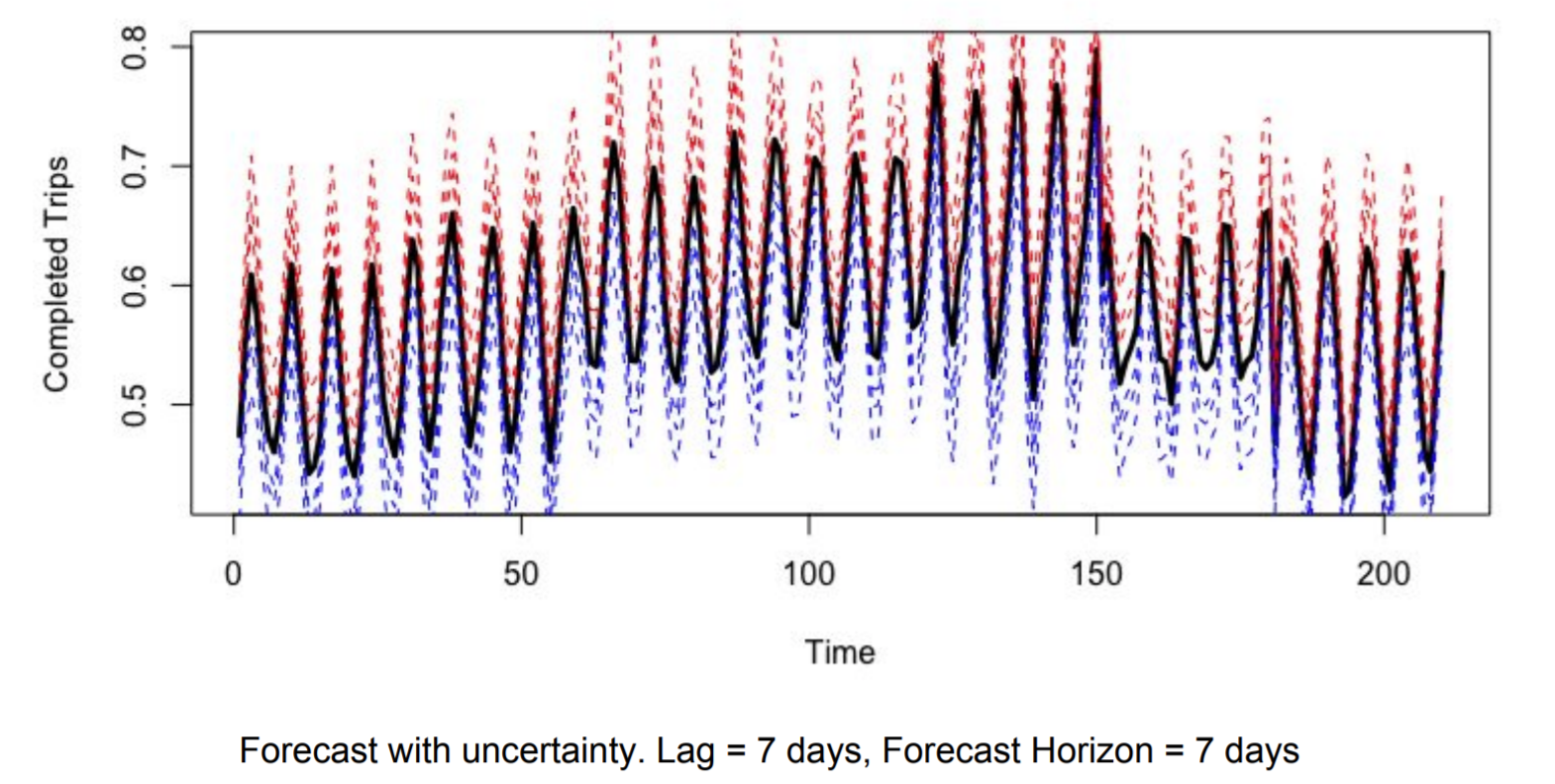
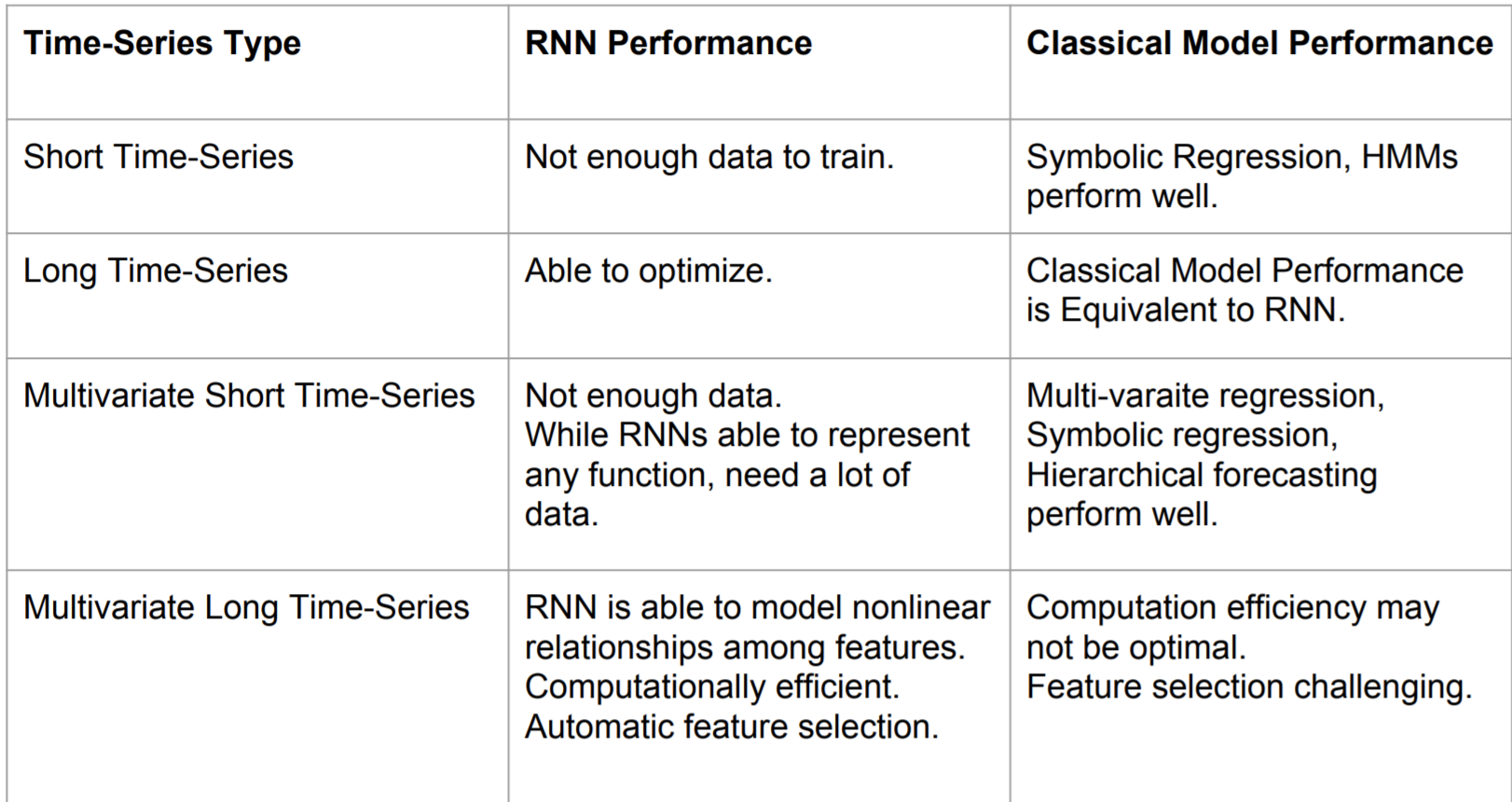
이렇게 두 개의 모델을 함께 써주면, 단일 LSTM forecaster 를 사용했을 때보다, 성능이 훨씬 좋아졌다고 한다. 마지막으로 여러 시계열 데이터에 대해 RNN 기반과 정통 통계 모델을 사용했을 때의 성능 차이는 아래와 같다고 한다.
neural network 기반의 모델이 기존의 모델보다 좋은 조건을 갖추기 위해서는
- 데이터가 많아야 한다 (many data)
- 차원이 커야 한다. (many features)
그래도, feature 간 관계가 없는 것을 가정하는 기존 모델과 달리, feature 간 nonlinear relationship 을 포착하고, 이를 활용하는 neural network 는 high-dimensional data 에서는 매력적인 것을 넘어, 필수적 선택 요소로 보인다.

Monitoring Data Quality at Scale with Statistical Modeling [원글]
Data Quality Monitor (DQM) 문제를 time-series feature 데이터에서의 anomaly detection task 로 푼다.
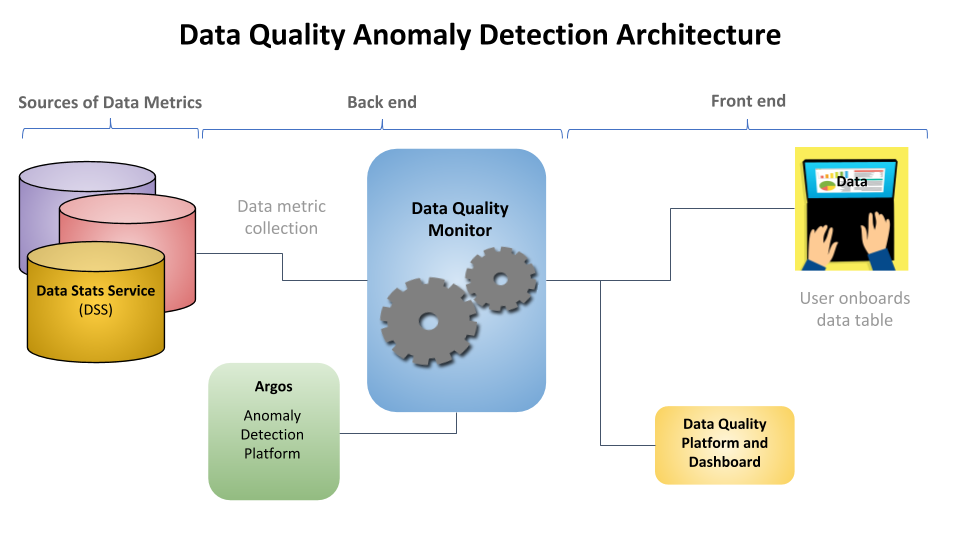
처음에 필요한 것은, 각 feature의 통계값을 저장해놓은 Data Stats Service(DSS) 이다. mean, median, min, max 과 같은 값들을 통해, data quality metric 을 Hive와 같은 data store 에 저장해놓는다.
이런 metric 을 시계열 순으로 읽게 되면, 상관관계가 높은 feature 들은 서로 높은 metric 상관관계를 보일 것이다. 따라서, 많은 feature 의 수를 이들의 공분산을 통해, 적은 수로 줄이는 dimensionality reduction을 PCA 기법으로 한다.
그렇게 되면, 원래 N개였던, feature 들의 시계열 anomaly detection을 해야 했지만, M개만 분석을 해도 되니, 분석이 훨씬 효율적이게 된다. (N >> M)
추가적으로, 각 PC 의 분산의 설명력은 anomaly detection의 예측에 영향을 주지 않는 쪽으로 하는 것이 성능이 더 좋았따고 한다. 즉, eigenvalue 의 영향을 없애준 것이다.
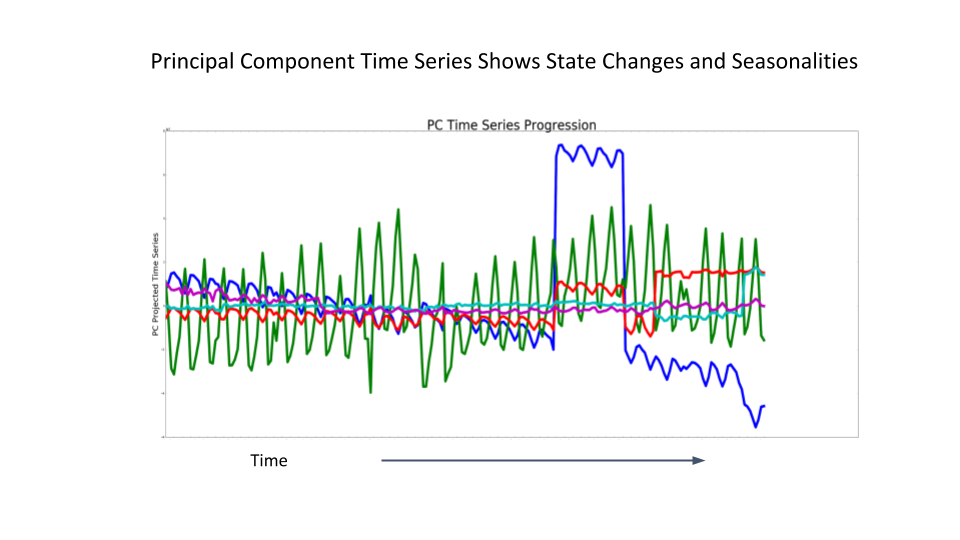
PC 를 통해, DSS 에서 읽은 데이터를 전처리 한 후에는, Holt-Winters 이라는 시계열 모델을 사용한다고 하는데, 추세를 고려한 지수 평활법이라고 한다. 여기서 이 모델이 무엇인지는 크게 중요하지 않으니, forecasting model 정도라고 생각하고 넘어가도 좋다.
중요한 건, forecasting model을 왜 anomaly detection에 사용했는가인데, 결국 forecasting 은 과거 데이터에 기반하기 때문에, 예측하기 전까지의 데이터 패턴을 보고, 통계적으로 가장 그럴 듯한 미래를 예측함으로써, 이를 크게 벗어나면, anomaly 라고 할 수 있다.
Conclusion
이번 글을 읽으면서, 느낀 것은 2020년도에 나온 포스트 기준, Uber 가 PySpark 와 Hive 를 적극적으로 활용한다는 부분에서, 해당 프레임워크가 데이터 파이프라인을 구축하는데 있어서 매우 유용, 중요 하는 것을 느꼈다.
또한 두 테스크에 대한 두 방법론이 모두, 차원 축소 + forecasting 모델 이라는 로직을 따르는데, 모델 이전에 feature extraction 을 해주는 프로세스를 내 리서치에도 적극적으로 도입해야 겠다는 생각이 들었다.
'[개발 정리] > [data engineering]' 카테고리의 다른 글
| SQL 프로그래밍 객체 : 함수, 저장 프로시저, 트리거 (1) | 2024.12.18 |
|---|---|
| [MlOps] Data Engineering in Uber (1) (0) | 2021.09.11 |
