
TechY
[논문 정리] Don’t Stop Pre-training: Adapt Language Models to Domains and Tasks 본문
[논문 정리] Don’t Stop Pre-training: Adapt Language Models to Domains and Tasks
hskimim 2020. 12. 28. 15:56LM 테스크를 통해 pre-train되는 큰 모델들은 domain의 편향없이 general-corpus 에서 학습되곤 한다. 하지만 finance 나 medical 분야 등 domain-specific corpus가 많고 그 의미 차이가 분명한 분야에서는 domain adaptation 의 방법으로 모델을 fine-tuning할 필요가 있다. 해당 논문은 pre-trained 모델에 네 가지 다른 도메인 데이터에 대한 pre-training 실험을 진행한 논문이다.
논문에서 진행한 실험은 아래와 같다.
1. DAPT (Domain-adaptitve pre-training)
2. TAPT (Task-Adaptive pre-training)
3. Curated-TAPT
0. 데이터
논문에서 사용한 domain-specific data는 아래와 같다. 표에 Domain 과 Task 로 데이터에 대한 설명이 계층적으로 존재하는 것을 볼 수 있는데, 예로 들면, Domain의 하위 집합으로 Task 가 있다고 생각하면 된다.
ex) BIOMED 분야 데이터에 RCT classification task 데이터가 존재

1. DAPT
DAPT는 데이터의 가장 큰 집합인 Domain에 대해서 pre-train 하는 것이다. pre-train은 Masked-LM 테스크를 통해 진행된다. 예상했던 것과 같이, baseline이 충분한 성능이 보여줌과 도시에, 전반적으로 도메인에 속해있는 task 에 대한 성능 (F1-score) 이 향상된 것을 확인할 수 있다. 흥미로운 부분은 ¬DAPT 부분이다. 논문에서는 DAPT 의 성능 향상이, domain 에 대한 pre-train이 아닌 단지 baseline 모델이 더 많은 데이터에 학습된 것에 따른 성능 개선인지에 대해 확인하려 하였다. 방법은 ir-relevant 한 도메인에 대해 학습을 시킨 후, 관심있는 도메인의 task의 성능을 보는 것이다. (ex. CS 로 학습 후, RCT task) 아래의 표를 보면, ¬DAPT 의 결과가 baseline 모델보다 좋지 않은 것을 알 수 있다. 즉, domain 에 속한 task 성능은 domain 에 대한 pre-train으로 개선될 수 있다.

2. TAPT
이번에는 DAPT보다 좀 더 흥미로운 TAPT이다. TAPT는 domain에 속해있는 Task 에 대해 pre-train을 진행하는 것으로 학습하는 데이터 수가 월등히 적다. (1/50000) 그럼에도 불구하고, 아래의 표를 보면, DAPT보다는 덜 하지만 baseline보다는 좋은 성과를 보여줌을 알 수 있다.
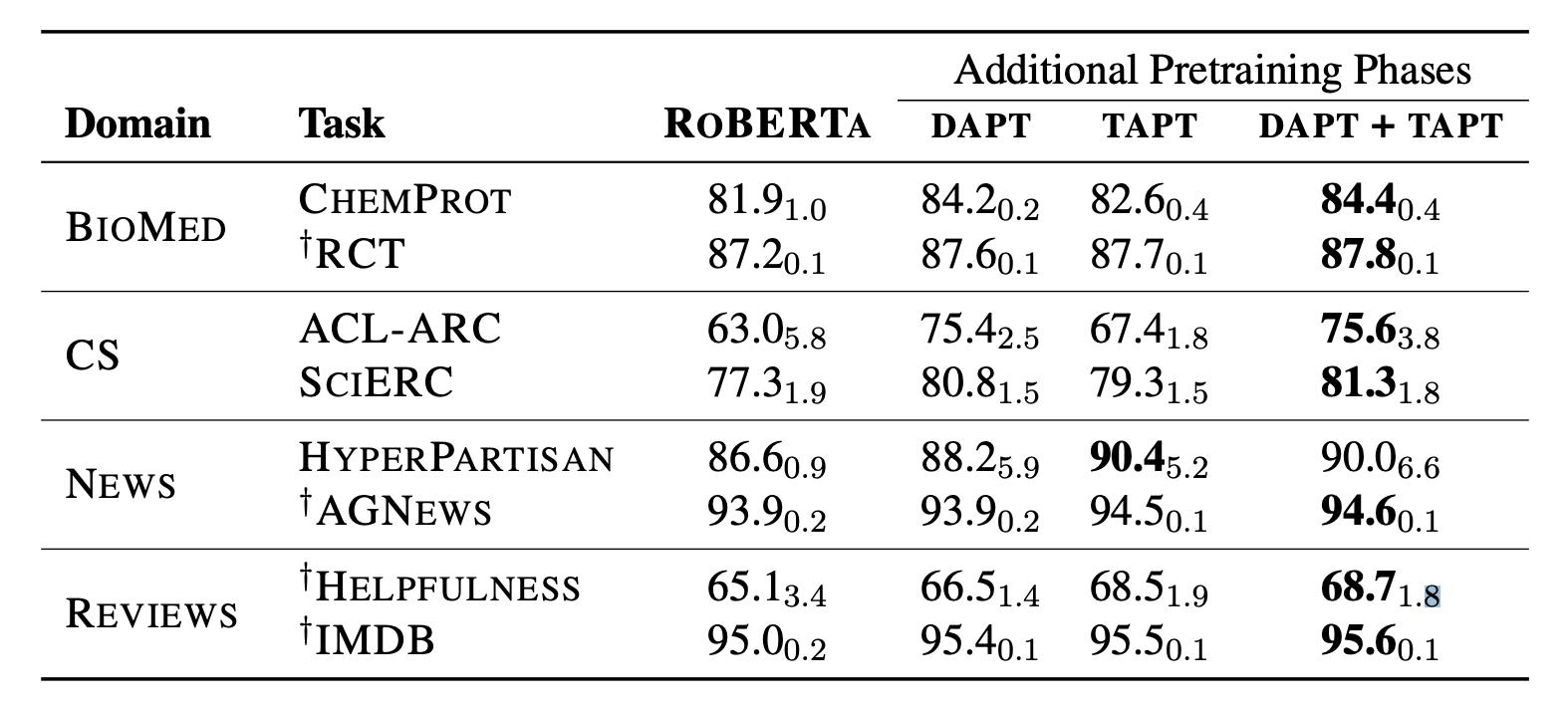
TAPT 실험에서 가장 흥미로운 부분은 task-transfer 이다. TAPT의 초반 설명 부분을 읽고 과연 같은 domain에 대한 다른 task에 대해서도 좋은 성과를 보여줄까라고 생각했는데, 아니나 다를까 실험이 있었다. 아래의 표를 보면, 같은 도메인임에도 불구하고 task를 바꿨을 때 성능이 나빠지는 모습을 보여준다. 즉, TAPT는 Domain을 대표하지 않는 Task만의 표현을 학습하는 경향이 존재한다.

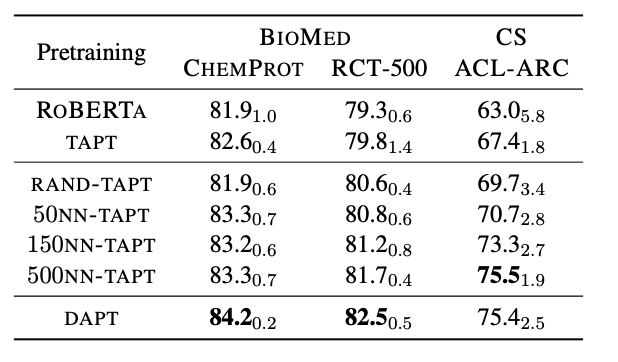
3. Curated-TAPT
위의 TAPT에서는 적은 데이터로도 Task 에 대해 개선된 성능을 보여줬지만, 학습되는 표현이 특정 Task 에 대해 over-fit 되는 경향을 보여주었다. 이에 따라, 논문에서는 trade-off 의 중간 지점을 목표로 하는 학습 방법을 제안한다.
우선 domain과 task에 해당하는 데이터를 하나의 임베딩 모델에 넣고 학습시킨다. (엄청난 문장 데이터가 학습되어야 하기 때문에, VAMPIRE 라는 가벼운 모델을 사용하였다.) 그 후, task 에 속한 각 데이터 셋과 유사한 K개의 domain 데이터 셋을 선택한다. 이에 따라 뽑힌 데이터는 task dataset과 분포가 유사한 domain dataset이 된다. 쉽게 말하면, task 를 대표할 수 있는 domain 데이터셋이 된다.
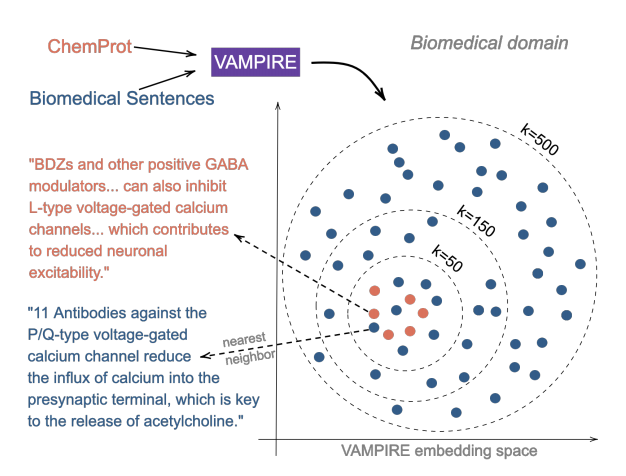
이에 다른 결과는 아래와 같다. 논문이 목표로 했던 것과 같이, TAPT와 DAPT의 중간 지점의 성능을 잘 보여주고 있다. TAPT보다 학습해야 하는 데이터는 늘어났지만, 여전히 DAPT보다는 확연히 적고 성능은 DAPT와 가깝게 증가하였다. (95% 정도)
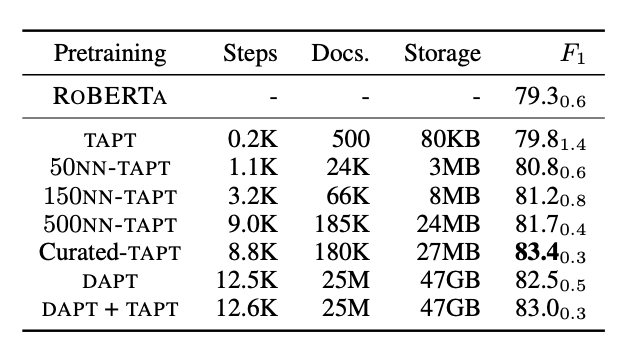
마지막으로, 각 pretraining 방법과 요구되는 computational cost 를 비교한 테이블이다. 논문의 주제는 Don't stop pre-training 이지만, 논문은 효율적인 pre-train 방법을 제시하였다.
'[논문 정리]' 카테고리의 다른 글
| [논문 정리] Generative Adversarial Networks (0) | 2021.01.17 |
|---|---|
| [논문 정리] Auto-Encoding Variational Bayes (0) | 2021.01.17 |
| [논문 정리]Sequence to Sequence Learning with Neural Networks (0) | 2020.12.26 |
| [논문 정리] Neural Machine Translation by Jointly Learning to Align and Translate (0) | 2020.12.26 |
| [논문 정리] A STRUCTURED SELF-ATTENTIVE SENTENCE EMBEDDING (0) | 2020.12.15 |



