
TechY
[논문 정리] Neural Machine Translation by Jointly Learning to Align and Translate 본문
[논문 정리] Neural Machine Translation by Jointly Learning to Align and Translate
hskimim 2020. 12. 26. 18:22Dzmitry Bahdanau와 조경현 교수님이 함께하신 논문 Neural Machine Translation by Jointly Learning to Align and Translate 논문에 대해 다뤄보도록 하겠습니다. 모든 내용과 이미지는 해당 논문을 참고합니다.
Abstract
RNN Encoder-Decoder 모델의 특성 상, information compression이 발생하고, 이에 따른 고정 길이 벡터의 보틀넥(bottleneck) 현상이 발생, 이에 다라, Encoder-Decoder 모델에서 더 나아가서 모델이 자동적으로 target sequence와 관련이 있는(유사한,relevant) source sequence를 찾게 하는 방법을 제시한다.
Introduction
이전 논문들이 제시한 RNN Encoder-Decoder 모델은 DNN 아키텍처의 새로운 관점을 보여주었지만, Sequence to Sequence 의 테스크에서 긴 문장에 대해 잘 대처하지 못하는 경향이 있다. 그 이유는 이전 모델들은 고정 길이의 벡터가 source sentence의 모든 정보를 압축할 수 있다는 전제를 내세웠기 때문이다.
이러한 문제에 따라서, 우리는 정렬(앞으로는 보다 직관적이고 정확한 표현을 위해 align 이라는 표현을 사용하겠습니다.)과 번역을 함께 진행하는 모델을 소개할 것이다. 해당 모델은 input sentnece를 고정 길이의 벡터가 아닌 sequence 벡터로 인코딩하고, 디코딩 과정에서 선별적으로 상황에 맞는 벡터들을 부분적으로 선택한다. 이러한 방법은 이전 RNN Encoder-Decoder 모델과 같이 가변 길이의 input, output 데이터에 대해 유연하게 대처할 수 있으며, 무엇보다 성능 개선에 높은 기여를 한다.
Learning to Align and Translate
p(yi|y1,...,yi−1,x)=g(yy−1,si,ci)p(yi|y1,...,yi−1,x)=g(yy−1,si,ci)
위의 식의 좌변은 전형적인 translate model의 conditional probability를 의미하는 것이고, 우변은 이전 논문에서 계속 제시해오던 식으로 해당 식을 최대화하는 방향으로 모델이 학습되어 왔다. 해당 논문은 우변의 cici 에 대한 새로운 관점을 제시한다.
eij=a(si−1,hj)eij=a(si−1,hj) 위의 식에서 우변의 si−1si−1이 의미하는 것은 Decoder 에서 i-1 시점에서의 hidden unit을 의미하고, hihi는 Encoder의 j 시점의 hidden unit을 의미한다. aa는 alignmentmodelalignmentmodel이라고 불리며, 두 hidden state가 얼마나 관련성이 있는지(relevant)에 대한 점수를 측정한다. 좌변의 eijeij에서 볼 수 있다시피, Encoder와 Decoder의 모든 step 간의 relevance 를 계산한다.(물론 j와 i는 다를 수 있다.)
αij=exp(eij)∑Txk=1exp(eik)αij=exp(eij)∑k=1Txexp(eik)
이런 계산을 하는 이유는 Decoder에서 특정(t시점) target sequence 가 어떠한 source sequence와 관련성이 짙은지에 대해 발견해내고 이에 집중하고 싶은 것이기 때문에, 확률 형태로 풀어준다. 이에 따라, 분모를 j에 대해 모두 더하게 만들고, Decoder의 i시점에 대한 확률값을 표현한다.
αijαij는 source word xjxj가 target word yiyi로 번역된 것 즉, align 되어 있을 확률을 나타낸다고 할 수 있다.
추가적으로 우리가 사용한 Encoder의 아키텍처는 Bi-RNN을 사용하였다. 그 이유는 이전의 단어들(preceeding words)에 대한 요약 정보뿐만 아니라, 앞으로 나올 단어들(following words)에 대한 함축 정보또한 지니게 하고 싶었기 때문이다. 이에 따라 Encoder가 반환하는 hidden units는 양쪽 방향에서 오기 때문에, 두 개가 나오게 된다. hj=[h⃗ Tj;h⃖ Tj]hj=[h→jT;h←jT]
Models and results
- Loss function : SGD
- Optimizer : Adadelta
- Batch_size : 80
- L2L2 norm of the gradient of the cost function : 1

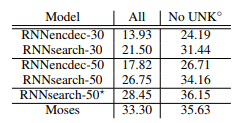
위의 두 표를 보면, RNNenc 는 기존 논문들이 제시해왔던 RNN Encoder-Decoder 모델이고, RNNsearch는 해당 논문이 제시하는 alignment and translate 모델이다. 뒤의 숫자는 문장의 최소 길이에 대한 문제이다. 즉, 긴 문장에 대한 번역 작업의 비교 테이블임을 알 수 있다. 볼 수 있다시피,문장의 길이가 길어지게 되면, 다른 모델들은 BLEU 성능이 급격하게 감소하지만 우리의 모델 성능은 강건하게 성능을 보여주고 있음을 알 수 있다.
두 번째 이미지의 표에서 No UNK 컬럼은 UNK토큰이 없는 문장, 즉 임베딩 벡터가 가지고 있는 vocab capacity에 부합하는 문장만을 트레이닝 했을 때의 성능을 의미한다.
Alignment
먼저 짚고 넘어갈 것은, soft alignment 와 hard alignment 간의 개념 정리이다. soft alignment 는 두 시퀀스 간의 각 단어에 대한 relevance 를 계산하는 식에서 파라미터를 학습 과정에서 함께 학습하는 것을 의미하고, hard alignment 는 고정된 파라미터를 사용해 학습 과정에 서 제외되는 것을 의미한다.

위의 히트맵은 target sentence의 각 단어들과 source sentence의 각 단어들간의 관계를 직관적으로 나타낸 표이다. 흥미롭게도, 표에서 나타나는 히트맵의 수치들이 단조롭지 않다는 것이다.(원문에는 non-trivial, non-monotonic alignments라고 표현합니다.) 그 이유는 영어와 불어 간에 형용사나 명사의 위치가 문장 내에서 같지 않기 때문이다. 즉, 어순이 다르기 때문이다. 하지만 우리의 모델은 어순의 변동 사안또한 잘 포착하고 있음을 단조롭지 않는 히트맵을 통해서 확인할 수 있다.
soft-alignment 와 hard-alignment 간의 차이점의 예시를 들자면, 영어의 “the” 는 불어로는 “l’“이며, “man”은 “homme”이다. hard alignment 의 경우 “the man”이라는 단어가 있으면, 이러한 단어들을 각각 분리해서 “l’”,”homme”로 번역하지만, soft alignment 의 경우에는 “the man”을 연결시켜서, “l’ homme”로 번역하게 된다. 즉 보다 자연스러운 문장 생성과 이에 따른 번역이 가능해진다는 것이다. 추가적인 이득으로는 자연스럽게 source , target 시퀀스 간의 가변 길이에 대처할 수 있다는 것이다.
Conclusion
alignment and translate jointly 는 soft alignment 를 의미합니다.
LSTM 과 같은 RNN 기반 모델 자체가 훌륭하게 해결해오지 못했던, 긴 문장에 대한 번역 성능에 대한 문제를, target sequence의 특정 word와 source sequence의 특정 word간의 alignment and translate jointly를 통해 long setence에 대한 성능 차이를 크게 보였다.
'[논문 정리]' 카테고리의 다른 글
| [논문 정리] Don’t Stop Pre-training: Adapt Language Models to Domains and Tasks (0) | 2020.12.28 |
|---|---|
| [논문 정리]Sequence to Sequence Learning with Neural Networks (0) | 2020.12.26 |
| [논문 정리] A STRUCTURED SELF-ATTENTIVE SENTENCE EMBEDDING (0) | 2020.12.15 |
| [논문 정리] Unsupervised Deep Embedding for Clustering Analysis (0) | 2020.12.15 |
| [논문 정리] A simple method for domain adaptation of sentence embeddings (0) | 2020.12.12 |



