
TechY
[논문 정리] Training Temporal Word Embeddings with a Compass 본문
논문 이름은 "Training Temporal Word Embeddings with a Compass" 이다. 시간에 따라 변화하는 단어의 의미들을 식별하는 Temporal word embedding 을 위한 모델이다. 이름은 줄여서 "TWEM" (Temporal Word Embedding Model) 이다. 코드는 저자의 깃헙을 참고하면 된다.
모델의 로직은 매우 간단하다. 해당 모델은 우선 인풋과 아웃풋을 context와 center로 하는 CBOW와 그 반대인 skip-gram을 기반으로 한다. 즉, TWEM의 인풋 중 하나가 pre-trained word2vec 모델이다.
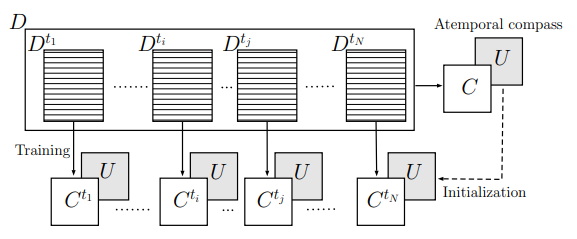
Word2Vec 모델에는 CBOW 기준 context vector들을 encode하는 weight parameter (위의 이미지에서 C) 있고, encoding 된 hidden representation을 center word 예측을 위해 decode하는 weight parameter(위의 이미지에서 U) rk 있다.
해당 모델은 위의 그림에서 볼 수 있다시피, 미리 학습된 Word2Vec 모델의 두 개 parameter matrix C, U 를 준비한다. 이 때 모델은 시간에 따라 학습된 것이 아닌 전체 기간에 대한 학습이 이뤄진다. (Atemporal) 즉, pre-trained Word2Vec에서 학습된 개별 단어 벡터들은 시간에 변하지 않는 static vector들이다.
그 후, 시간에 따라 데이터 chunk 들을 준비해두고 output parameter U는 고정한 상태에서 시간 배치에 따라 C_{t} 를 학습시킨다. Distributional Hypothesis 에 따라 단어들의 상대적 위치(분포)가 중요한 것이기 때문에, 위치 정보를 pre-trained 된 좋은 initial point에서 학습할 수 있게 된다. 무엇보다, U를 고정시킴에 따라, 각 C_{t} 들은 같은 벡터 공간에 놓일 수 있게 되어 C_{t} 간의 비교 연산이 가능하다.
'[논문 정리]' 카테고리의 다른 글
| [논문 정리] A STRUCTURED SELF-ATTENTIVE SENTENCE EMBEDDING (0) | 2020.12.15 |
|---|---|
| [논문 정리] Unsupervised Deep Embedding for Clustering Analysis (0) | 2020.12.15 |
| [논문 정리] A simple method for domain adaptation of sentence embeddings (0) | 2020.12.12 |
| [논문 정리] Diverse mini-batch Active Learning (1) | 2020.11.28 |
| [논문 정리] Active Learning Literature Survey (0) | 2020.11.28 |



