
TechY
[논문 정리] Intriguing properties of neural networks 본문
말그대로 흥미로운 논문이다. 소스 코드는 깃헙을 참고하였다.
논문에서 진행한 연구는 크게 2가지로 나눌 수 있다.
1. Neural Network 모델이 학습한 representation은 individual unit 이 아닌, space에서 유의미하다.
2. Neural Network 모델은 input-output mapping에 있어서 상당히 불연속적인 모습을 보여주며, 이에 따라, 인식하기 어려운 pertubatation을 통해서도 pretrained model의 기존 의사결정을 바꿀 수 있음을 보인다.
1. Units of: φ(x)
Neural Network 모델의 특징 중 하나는 feature representation이라고 할 수 있다. 즉, 특정 input을 사용자에 의해 정해진 차원 크기의 vector space로 표현된다는 것이다. 이 때, 특정 vector에 할당되어 있는 single feature를 추출하여 그 차이를 분석한다면 해석에 있어 도움이 될 것이다. 논문에서 저자는 직관적인 연구를 진행하는데, pretrained model이 특정 입력값에 대해 뱉은 출력값 D차원 벡터를 N개 모은다. [N, D]
그 후, hidden 차원 D에 대해서 가장 높은 값들을 K개를 뽑아 나열하면서 각 차원 축들이 나타내는 값들이 무엇인지를 휴리스틱하게 판단한다. 만약 벡터의 각 차원이 semantic information이 있다면, 차원별로 높은 값이 있는 입력값들은 저마다의 특정을 가질 것이다.
이에 반하는 실험으로는, 입력값 [N, D] 에 [D,1] 차원을 가지는 random initialized vector를 내적한 후, 가장 높은 값 K를 뽑는다. 이전의 실험이 natural basis 상에서 입력값을 뽑았다면, 해당 실험은 random direction에서 입력값을 뽑은 것이다. 이에 따라, 만약 두 실험의 결과값이 큰 차이가 없다면individual unit에는 semantic information의 측면에서 큰 의미가 없음을 의미한다.
논문의 결과에 따르면, Mnist를 CNN 모델에 학습시켰을 경우, 두 실험 결과가 서로 유사했고, ImageNet을 AlexNet에 학습시킨 경우에는 두 경우 모두, 각자의 feature를 잘 나타냈다고 한다. 개인적으로, 실험의 결과 요인이 모델 때문인지 데이터의 복잡성에 달린 것인지 알기 어렵다는 것에 조금은 아쉬운 실험이라고 생각한다.
첨부한 깃헙에도 Mnist 에 대한 연구가 있어 필자는 이미지가 아닌 텍스트 데이터로 같은 실험을 진행해보았다. Word2Vec 모델을 학습하여 진행하였고, 모델 학습 코드는 아래와 같다.
import gensim.downloader as api
corpus = api.load('text8')
from gensim.models.word2vec import Word2Vec
model = Word2Vec(corpus)실험에 있어 한 가지 옵션을 추가하였는데, 아래 이미지와 같이 개별 word vector의 크기는 학습된 단어의 frequency에 비례한다. 즉, word frequency 정보가 vector에 녹아 있기 때문에, 실험에 있어 이를 통제하기 위해 normalized vector와 raw vector를 모두 확인하였다. 미리 언급하자면, 해당 실험의 한계로는, 이미지 데이터의 경우 인식하기 상대적으로 쉬우며 무엇보다 이미지 당 라벨이 할당되어 있지만, 단어의 경우에는 휴리스틱하게 적용할 수밖에 없다는 부분이 있다.

raw word vector (~5th dimensions)
| 1 | million | site | come | files |
| 2 | wars | troops | border | between |
| 3 | upon | reason | song | though |
| 4 | stations | my | satellite | traffic |
| 5 | be | than | many | pre |
randomly projected word vector (~5th dimensions)
| 1 | estimated | age | married | league |
| 2 | been | worked | become | came |
| 3 | ratio | has | estimated | population |
| 4 | did | million | cost | saw |
| 5 | number | world | man | years |
normalized word vector (~5th dimensions)
| 1 | avanti | phasing | compiled | interviews |
| 2 | slavs | crusaders | peace | syria |
| 3 | donation | reason | greeson | saints |
| 4 | station | flooded | traffic | traveling |
| 5 | lynx | bronze | lighthouse | celtic |
randomly projected with normalized word vector (~5th dimensions)
| 1 | lusthog | surprise | would | showed |
| 2 | happened | saw | exploded | showed |
| 3 | hope | chances | chance | got |
| 4 | flight | bombers | troop | flew |
| 5 | unemployed | adult | married | females |
본 논문에서도 언급했던 것과 같이 word2vec 모델은 vector space에 표현된 특정 단어의 다양한 방향들이 자연어 표현에 도움이 된 것에 반해 실험 결과는 single unit이 상대적으로 단어의 특성을 잘 내재한 것 같은 결과가 나왔다. 또한 두 경우 모두, word vector 를 normalized 한 것이 단어들의 특성을 잘 묶어주는 것으로 보인다.
2. Blind Spots in Neural Networks
Neural Network 모델은 training examples과 정확히 일치하지 않아도, 이와 근접한 데이터에 대해 일반화를 잘 수행한다고 알려져 있다. (local generalization) 수식으로 표현하면, training examples x에 학습한 모델은 ||r|| < epsilon 에 있어서 x + r 에 대해 일치하는 예측값을 할당한다는 것이다. 이를 smootheness prior 라고 하며, computer vision 분야에서 해당 prior 가 유효함이 알려져 있다.
하지만, 저자는 간단한 optimization을 통해서 모델이 misclassify 하게 만드는 pertubation term "r" 을 찾을 수 있다고 말한다. 이렇게 나온 데이터를 adversarial examples 이라고 말하며, 이를 data augmentation에 사용하여 기존 기법보다 모델의 강건성과 수렴성에 기여할 수 있다고 말한다.
모델의 목적 함수는 아래와 같다.

즉, r 의 capacity를 줄이며, 동시에 r perturbation이 더해진 adversarial examples 이 corrputed label에 대해 예측력을 높게 만드는 것이다. x+r 의 값은 모든 픽셀 포인트에 대해서 0 또는 1의 binary 값만 가질 수 있게 함으로써, scaling 을 맞춰준다. (참조한 깃헙에서는 clipping 을 사용하였다.)
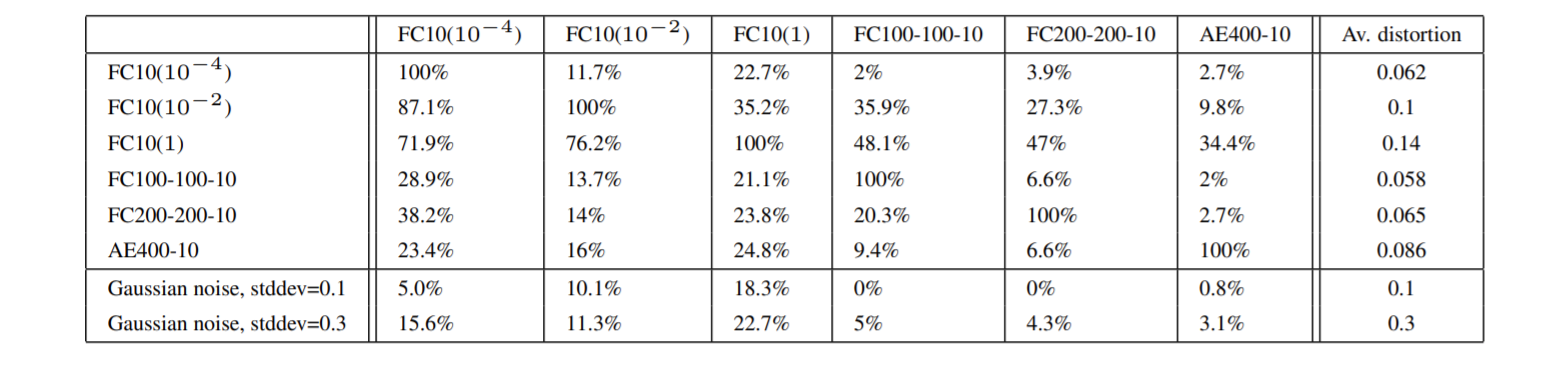
위의 표가 의미하는 것은 column에 있는 모델을 통해 훈련된 r 로 x+r 를 만들고, row 에 있는 모델로 test error 를 계산한 결과이다. 모델 별로 adversarial examples 에 대한 대응 정도가 다르지만, 전반적으로 misclassify 되는 경향을 보인다.
'[논문 정리]' 카테고리의 다른 글
| [논문 정리] Deep Metric Learning: A Survey (3) | 2021.06.09 |
|---|---|
| [논문 정리] Learning both Weights and Connections for Efficient Neural Networks (0) | 2021.06.01 |
| [논문 정리] Generative Adversarial Networks (0) | 2021.01.17 |
| [논문 정리] Auto-Encoding Variational Bayes (0) | 2021.01.17 |
| [논문 정리] Don’t Stop Pre-training: Adapt Language Models to Domains and Tasks (0) | 2020.12.28 |



