
TechY
[논문 정리] Learning both Weights and Connections for Efficient Neural Networks 본문
[논문 정리] Learning both Weights and Connections for Efficient Neural Networks
hskimim 2021. 6. 1. 01:49최근 model compression 에 관심이 생겨, 논문을 찾아보던 와중, 인용 수가 높아보여서 읽어본 논문이다. 코드는 해당 깃헙을 참고하였다. 해당 논문은 network pruning 기법을 사용한다. network pruning 이란 가지치기라는 말과 마찬가지로, neural network 가 가지고 있는 weight matrix 의 중요도를 계산한 이후, 상대적으로 중요도가 낮은 neuron 또는 connection을 masking 하는 기법이다. 해당 논문에서는 그 중, 파라미터인 neuron을 마스킹하는 방법을 사용한다.

논문이 제시한 학습 순서는 아래와 같다. 우선, 우리가 가지고 있는 모델을 학습한다. (pre-trained model도 좋은 선택이다.) 흥미로운 부분이 있는데, 논문의 표현을 빌리자면 "Unlike conventional training, however, we are not learning the final values of the weights, but rather we are learning which connections are important." 라는 문구가 있다. 제일 처음 모델을 학습시킬 때, 어떤 connection 들이 중요한지를 알아내기 위한, 장치가 별도로 없었는데, 이런 말이 쓰여져 있는 것을 보고 모델 학습에 따른 weight 값들을 보는 관점을 의미하는 것인가 라고 생각이 들었다. 실제로도, 특정 neuron 의 norm 이 클 수록, consistency 가 높으며, 이에 따라 중요도를 의미한다고 볼 수 있으니 말이다.
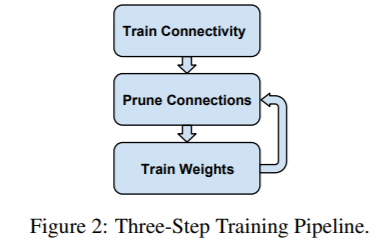
이렇게 처음 정의된 weight matrix 를 가지고 pruning 을 진행한다. pruning 의 기준은 neuron 의 norm 이 특정 threshold 를 넘어섰는가에 대한 것이다. 참고한 코드 구현에서는 아래와 같은 방법으로 prune 을 구현하였다.
grad 가 흐르지 않게 만든 mask 라는 layer 를 convolution filter와 같은 크기로 만든 후에, 이 둘을 1대 1로 곱해주는 것이다. 이에 따라, threshold 를 넘지 못한, 파라미터는 mask layer 에 의해 0으로 masking 된다.
def __prune__(self, threshold):
self.mode = "prune"
self.mask1.weight.data = torch.mul(
torch.gt(torch.abs(self.conv1.weight), threshold).float(), self.mask1.weight
)
self.conv1 = nn.Conv2d(
in_planes,
expansion * planes,
kernel_size=kernel_size,
stride=stride,
bias=False,
)
self.mask1 = nn.Conv2d(
in_planes,
expansion * planes,
kernel_size=kernel_size,
stride=stride,
bias=False,
)
self.conv1.weight.data = torch.mul(self.conv1.weight, self.mask1.weight)이렇게 마스킹을 시킨 후, 초기화를 하지 않은 상태에서, retrain을 하게 된다. (re-training without re-initialization) 초기화를 하고 re-train을 하게 되면, 기존 모델에 비교하여 성능이 크게 낮아진다고 한다. 이는 현재 초기화되고 계속 학습되고 있는 모델에 특화되어 pruning 이 진행되고 있는 것이기 때문에, 자연스러운 결과라고 생각한다. pruning 이 되는 weight는 initialize 가 될 때마다 달라질 수 있다고 생각한다. (구현을 해봐야겠다. 이건..)
추가적으로 L1 regularization보다 L2 regularization을 사용했을 때가 더 Accuracy loss 가 적다고 했는데, 실험적으로만 보였다. re-train을 하지 않고 pruning 만 했을 때에는 L1 을 적용했을 때가 더 좋았다고 한 것으로 보아, L1 보다 좀 더 자연스럽게 weight 를 smoothing 시키는 L2 가 안정적인 re-training 에 기여하지 않았을까 생각이 든다.
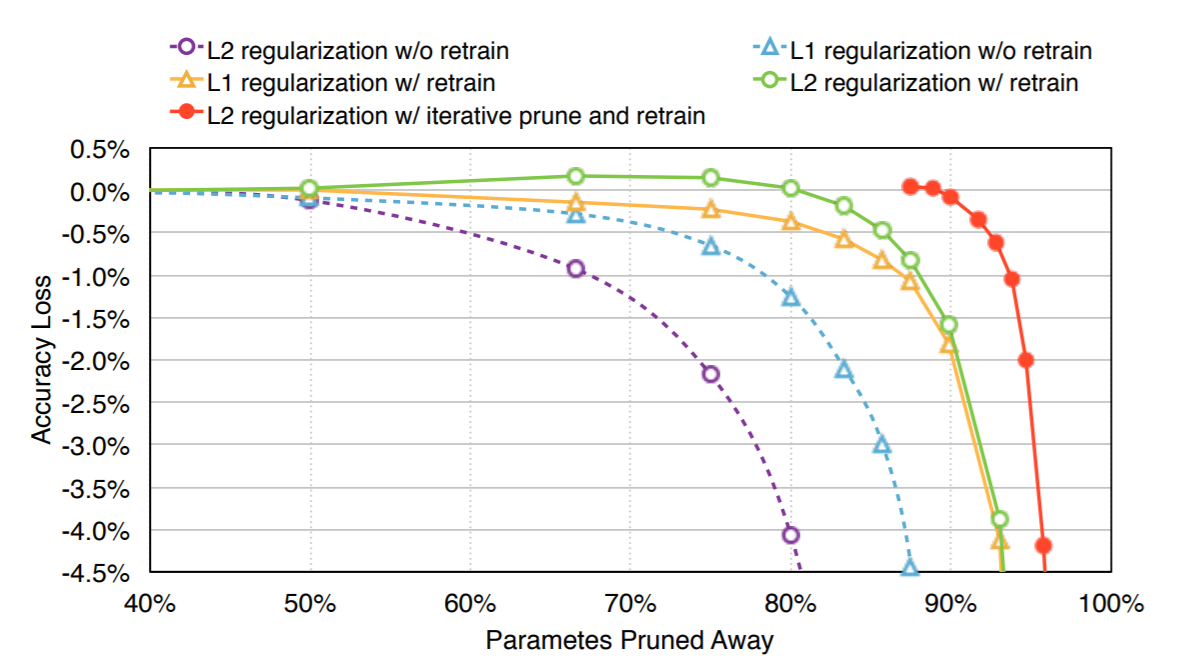
위의 사진을 보면, L2 regularization을 사용해서, iterative pruning 을 적용했을 때, 가장 효율적인 pruning 이 가능했음을 알 수 있다. 근데 가장 고무적인 것은 어떤 방법을 사용하든, 50% 정도의 파라미터가 pruning 될 수 있다는 것이며, 이는 neural network 에서 대부분의 파라미터가 abundant 함을 시사한다.
실질적으로 연구를 하다보면, 1%~2%의 성능보다 빠른 연산 속도와 가벼운 메모리 사용이 필요할 때가 더 많은 것 같다. 감당할 수 있을 정도의 Accuracy Loss 에 비해 효과적인 model compression은 임베디드 뿐만 아니라, 다양한 연구 환경 세팅에도 유용하게 사용될 수 있을 것 같다.
'[논문 정리]' 카테고리의 다른 글
| [논문 정리] mixup: BEYOND EMPIRICAL RISK MINIMIZATION (0) | 2021.06.11 |
|---|---|
| [논문 정리] Deep Metric Learning: A Survey (3) | 2021.06.09 |
| [논문 정리] Intriguing properties of neural networks (0) | 2021.02.22 |
| [논문 정리] Generative Adversarial Networks (0) | 2021.01.17 |
| [논문 정리] Auto-Encoding Variational Bayes (0) | 2021.01.17 |



