
TechY
[논문 정리] HEAD2TOE: UTILIZING INTERMEDIATE REPRESENTATIONS FOR BETTER TRANSFER LEARNING 본문
[논문 정리] HEAD2TOE: UTILIZING INTERMEDIATE REPRESENTATIONS FOR BETTER TRANSFER LEARNING
hskimim 2022. 1. 19. 05:19논문 링크 : [link]
transfer learning 학습 방법이 딥러닝 분야에서 널리 쓰이면서, huggingface나 timm과 같은 pretrained big-model을 제공해주는 라이브러리도 많아지고 있다. 이에 따라, 실무자들은 각자에게 맞는 테스크와 데이터에 맞게, 모델을 재학습시킨다.
이 때 여러 방법들이 있는데, 첫 번째로는, fine-tuning 방식이다. 이는 작은 학습률로 모델의 전체 파라미터를 업데이트하는 방식으로, 이전 실험에 따르면, 가장 좋은 학습 결과를 가져다준다고 한다.
두 번째로는 linear probing 이라고 하는 방식으로, output head 만 바꿔서, 마지막 linear layer만 재학습시키는 방식이다. 이는, pretrained layer를 업데이트하지 않고 그대로 사용하는 것으로, upstream training 에 사용된 data/task 의 분포가 downstream의 경우와 유사하다면, 적은 리소스로 효과적인 성능을 보일 수 있는 방식이다.
linear-probing의 성능이 fine-tuning과 크게 다르지 않다면, linear-probing을 쓰는 것이 훨씬 더 합리적이다. 그렇다면 fine-tuning의 성능을 outperform하게 하는 요인이 어디서 올까? 이에 대한 대답으로 논문의 저자는 "fine-tuning 방식은 새로운 representation을 찾는게 아닌, 기존에 학습된 표현들의 internal representations에 도움을 받는다" 라고 말한다. 즉, "knowledge transfer에 필요한 feature는 이미 internal feature에 다 있고, 이를 충분히 사용할 수 있다면 fine-tuning 하지 않아도 된다." 라고 말하는 것이다.
따라서, 해당 논문은 pretrained model의 마지막 layer값뿐만 아니라, internal representation 모두 또는 중요하다고 여기는 일부를 linear-probing을 위한 입력값으로 사용한다. 밑의 내용들은 internal representation의 사용이 transfer learning에 어떤 영향이 있는 지에 대한 실험과 결과에 대한 정리이다.

위의 등식을 먼저 짚고 넘어가보자. Domain Affinity라고 불리는 measure는 마지막 layer만 사용한 linear probing의 결과과 scratch 학습 방법, 즉 pretrained 모델을 사용하지 않고, target domain data만을 사용하여 학습시킨 경우보다 얼마나 outperform 하는지에 대한 것이다. 해당 값이 높을 수록, 마지막 layer 표현 방법이 knowledge transfer에 충분한 feature를 담고 있음을 시사하고, 이는 internal representation을 사용하는 것에 대한 인센티브가 줄어듬을 이야기한다. 즉, 낮을 수록, internal representation을 써야 할 이유가 생긴다.

위 그림을 이해하기 위해 오른쪽 아래 테이블에 있는 세 가지 다른 method를 다뤄보겠다.
- Linear : 마지막 layer의 feature representation만을 사용한 linear-probing
- Control : 다른 random seed를 사용해, pretraining한 다른 두 모델의 마지막 layer feature representation을 concat하여 linear probing (ensemble의 효과가 있음)
- Oracle : 마지막 layer feature representation과 internal representation 중 한 가지 representation을 concat하여 linear probing 하되, 가장 성능이 좋았던 조합을 선정
위 그림의 왼쪽 scatterplot 을 보면, X축의 Domain Affinity와 Delta Accuracy 가 음의 상관을 가짐을 알 수 있다. 즉, Domain Affinity가 높을 수록, internal representation의 효과가 0으로 가며, 반대의 경우에는 효과가 선형적으로 증가한다. (pearson correlation : -0.75)
Oracle과 같은 방법으로 grid-search에 따라 최적의 feature를 찾는 것은 cost가 많이 들 것이다. 이에 따라, 저자는 모든 internal representation을 다 쓰되 overfitting을 방지와 feature selection을 위한 정규화 방법, group lasso를 사용한다.
internal feature을 합치는 수식적 표현은 아래와 같다. 주목할 점은 equation 3 우변에 있는 a(.) 인데, 이는 각 representation에 대한 post-processing으로, 각 layer에 있는 feature를 concat하면, 최종 차원이 매우 커질 것이므로, 개별적으로 차원축소를 strided average pooling을 통해 진행해주고, feature 별로 norm이 다르면, linear 모델을 학습할 때 해당 부분이 dominate하게 되기 때문에, 각 feature별로 normalize를 시켜준다.
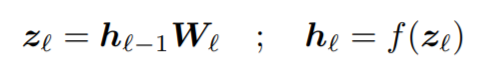

아래는 group lasso 페널티 항에 대한 식으로, 일반 lasso과 같이 정규화 과정에서 중요도가 떨어지는 feature의 계수를 0으로 만들되, feature들을 그룹으로 지어 같이 0으로 만들어주는 역할을 한다고 한다.


위의 테이블은 ResNet-50, 아래는 ViT-B/16 에 대한 모델의 성능 평가 테이블이다. 참고로 All+l_{1}|{2} 는 모든 internal representation을 concat하고 ridge나 lasso 정규화를 진행한 것이다. 즉, feature selection을 하지 않은 버젼이다.
애초에 fine-tuning을 이기려고 제안한 방법론이 아니니, 볼드체로 많이 선택받지 못했다는 것에 대해 신경쓸 필요는 없을 것 같다는 생각이 든다.
주목할 점은, 가장 오른쪽의 Mean 컬럼을 보면, 마지막 layer만을 사용한 Linear 보다, internal representation을 일단 다 쓰면, 성능이 크게 상승하는 것을 확인할 수 있으며, 이는 Fine-tuning과 크게 차이가 나지 않는다는 점이다.
간단한 아이디어임에도 불구하고, 다양하고 자세한 리서치들을 논문 안에 담아두어 친절하고 궁금증을 많이 남겨두지 않게 해주는 논문이였다. 해당 논문을 구현하여 pretrained model들을 다시 가공하여, feature store 같이 만들어두어도 좋겠다는 생각이 든다.
'[논문 정리]' 카테고리의 다른 글
| The Kelly Criterion and the Stock Market (0) | 2024.05.26 |
|---|---|
| [논문 정리] DEEP TEMPORAL CLUSTERING: FULLY UNSUPERVISED LEARNING OF TIME-DOMAIN FEATURES (0) | 2021.07.19 |
| [논문 정리] k-Shape: Efficient and Accurate Clustering of Time Series (1) | 2021.07.18 |
| [논문 정리] Translation in Multi-modal Learning 논문 정리 (0) | 2021.06.23 |
| [논문 정리] mixup: BEYOND EMPIRICAL RISK MINIMIZATION (0) | 2021.06.11 |



